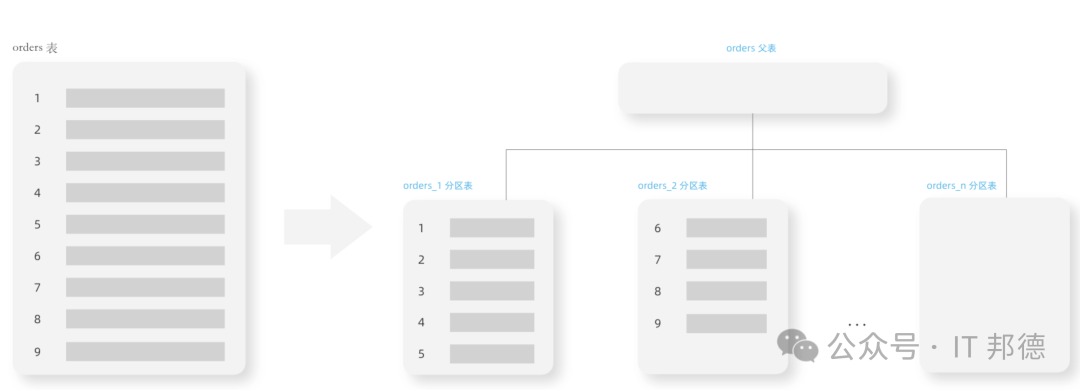
创建父表 CREATE TABLE orders ( id serial, user_id int4, create_time timestamp(0) ) PARTITION BY RANGE(create_time);
创建分区表 CREATE TABLE orders_hisotry PARTITION OF orders FOR VALUES FROM ('2000-01-01') TO ('2020-03-01'); CREATE TABLE orders_202003 PARTITION OF orders FOR VALUES FROM ('2020-03-01') TO ('2020-04-01'); CREATE TABLE orders_202004 PARTITION OF orders FOR VALUES FROM ('2020-04-01') TO ('2020-05-01'); CREATE TABLE orders_202005 PARTITION OF orders FOR VALUES FROM ('2020-05-01') TO ('2020-06-01'); CREATE TABLE orders_202006 PARTITION OF orders FOR VALUES FROM ('2020-06-01') TO ('2020-07-01');
在分区上创建索引 CREATE INDEX order_idx_history_create_time ON orders_history USING btree(create_time); CREATE INDEX order_idx_202003_create_time ON orders_202003 USING btree(create_time); CREATE INDEX order_idx_202004_create_time ON orders_202004 USING btree(create_time); CREATE INDEX order_idx_202005_create_time ON orders_202005 USING btree(create_time); CREATE INDEX order_idx_202006_create_time ON orders_202006 USING btree(create_time);
postgres=# CREATE TABLE cities ( city_id bigint not null, name text not null, population bigint ) PARTITION BY LIST (name);
CREATE TABLE cities_1 PARTITION OF cities FOR VALUES IN ('A'); CREATE TABLE cities_2 PARTITION OF cities FOR VALUES IN ('B'); CREATE TABLE cities_3 PARTITION OF cities FOR VALUES IN ('C'); CREATE TABLE cities_4 PARTITION OF cities FOR VALUES IN ('D');
postgres=# \d+ List of relations Schema | Name | Type | Owner | Size | Description --------+-------------------------------+-------------------+----------+------------+------------- public | cities | partitioned table | postgres | 0 bytes | public | cities_1 | table | postgres | 8192 bytes | public | cities_2 | table | postgres | 8192 bytes | public | cities_3 | table | postgres | 8192 bytes | public | cities_4 | table | postgres | 8192 bytes | (5 rows)
CREATE TABLE emp_0 PARTITION OF emp FOR VALUES WITH (MODULUS 3,REMAINDER 0); CREATE TABLE emp_1 PARTITION OF emp FOR VALUES WITH (MODULUS 3,REMAINDER 1); CREATE TABLE emp_2 PARTITION OF emp FOR VALUES WITH (MODULUS 3,REMAINDER 2);
🚀 3.分区表常用命令
查看分区表和每个分区的行数 SELECT relname,reltuples as rows FROM pg_class WHERE relname IN ('emp','emp_0','emp_1','emp_2') ORDER BY relname;
从分区表中分离分区 ALTER TABLE emp DETACH PARTITION emp_0;
重命名分区 ALTER TABLE emp_0 RENAME TO emp_0_bkp;
添加新的分区 ALTER TABLE table_name ADD PARTITION partition_name VALUES LESS THAN ('value');
删除现有的分区 ALTER TABLE table_name DROP PARTITION partition_name;
查看所有分区信息 SELECT * FROM pg_partitions WHERE tablename = 'table_name';






 400 186 1886
400 186 1886