一站式社交平台数据抓取利器MediaCrawler
|
freeflydom 2024年3月27日 17:48
本文热度 1910
2024年3月27日 17:48
本文热度 1910
|
前言
一站式社交平台数据抓取利器,带你玩转小红书、抖音、快手、B站和微博数据分析
不经意间,来查看MediaCrawler仓库源码,发现作者已经删库了。看来是领奖了。才几天不到的时间Star数量已经直逼10K了,增长速度近乎疯狂。
前两天只是将代码下载下来了,还没认真的玩。还好代码本地已经有了。如果有兴趣的也可以来找我要,免费的哟。
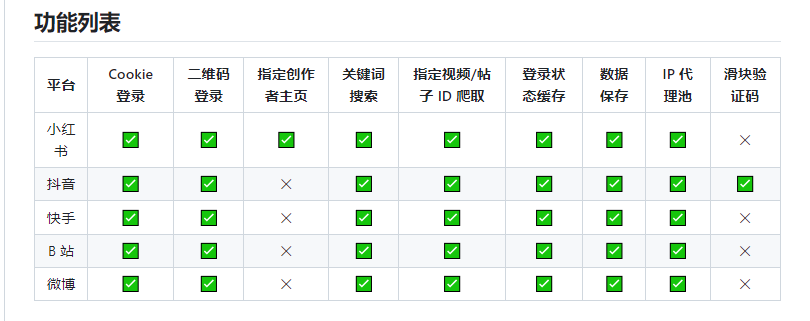
作者在这里也明显进行了标注使用了无头浏览器
那到底什么事无头浏览器呢?
无头浏览器(Headless Browser)是一种浏览器程序,没有图形用户界面(GUI),但能够执行与普通浏览器相似的功能。无头浏览器能够加载和解析网页,执行JavaScript代码,处理网页事件,并提供对DOM(文档对象模型)的访问和操作能力。
与传统浏览器相比,无头浏览器的主要区别在于其没有可见的窗口或用户界面。这使得它在后台运行时,不会显示实际的浏览器窗口,从而节省了系统资源,并且可以更高效地执行自动化任务。
常见的无头浏览器包括Headless Chrome(Chrome的无头模式)、PhantomJS、Puppeteer(基于Chrome的无头浏览器库)、playwright等。它们提供了编程接口,使开发者能够通过代码自动化控制和操作浏览器行为。
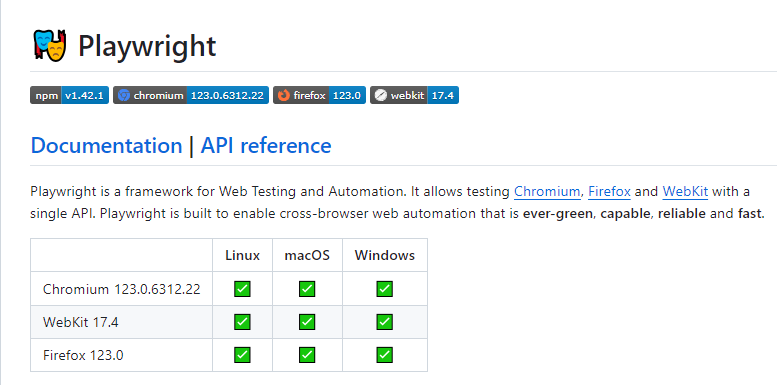
如果您比较Playwright和 Puppeteer的贡献者页面 ,您会注意到Puppeteer的前两个贡献者现在在 Playwright 上工作。Puppeteer 团队实质上是从 Google 转移到 Microsoft 并成为 Playwright 团队。
因此,Playwright 在很多方面与 Puppeteer 非常相似。API 方法在大多数情况下是相同的,并且默认情况下 Playwright 还捆绑了兼容的浏览器。
Playwright 最大的区别在于跨浏览器支持。它可以驱动 Chromium、WebKit(Safari 的浏览器引擎)和 Firefox。
无头浏览器其实就是看不见的浏览器,所有的操作都要通过代码调用 API 来控制,所以浏览器能干的事儿,无头浏览器都能干,而且很多事儿做起来比标准的浏览器更简单。
能够干什么呢?
我举几个常用的功能来说明一下无头浏览器的主要使用场景
自动化测试: 无头浏览器可以模拟用户行为,执行自动化测试任务,例如对网页进行加载、表单填写、点击按钮、检查页面元素等。
数据抓取: 无头浏览器可用于爬取网页数据,自动访问网站并提取所需的信息,用于数据分析、搜索引擎优化等。
屏幕截图: 无头浏览器可以加载网页并生成网页的截图,用于生成快照、生成预览图像等。
服务器端渲染: 无头浏览器可以用于服务器端渲染(Server-side Rendering),将动态生成的页面渲染为静态HTML,提供更好的性能和搜索引擎优化效果。
生成 PDF 文件:使用浏览器自带的生成 PDF 功能,将目标页面转换成 PDF 。
这个仓库如何使用呢
首先这是一个Python库,当然要安装必要的Python环境,这个我就不多说了,通过GPT或者在网上搜索都可以进行安装好。
接下来就是拿到代码后如何使用,这个其实作者也是非常的友好了,直接看README。
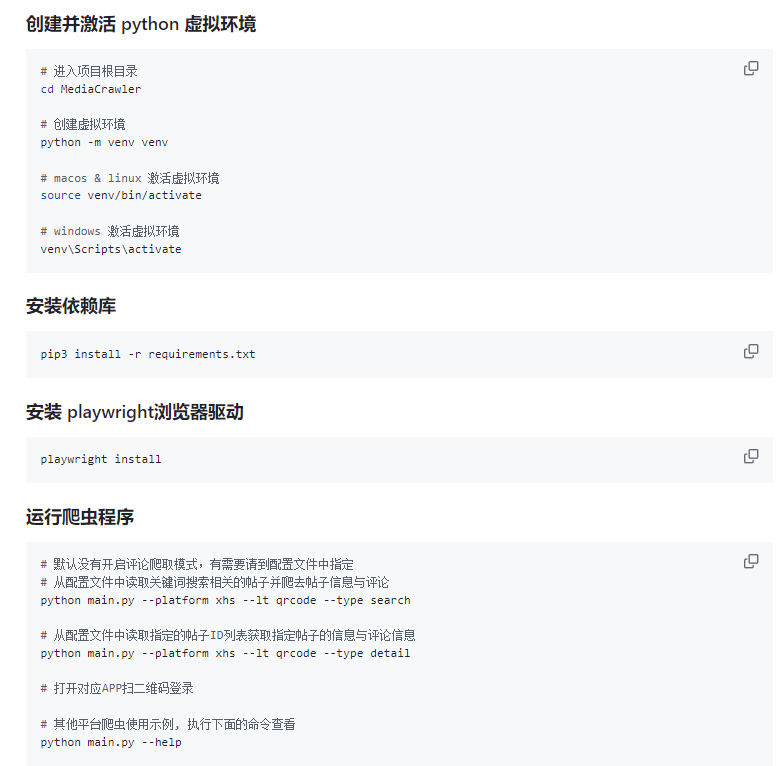
最后运行命令后,会出现一个二维码,比如这里我测试的是小红书,出现二维码之后,我们用小红书App来扫描,并进行确认身份,这样无头浏览器就能识别并记住我们的身份信息,后续就可以通过该身份进行抓取一些数据了。
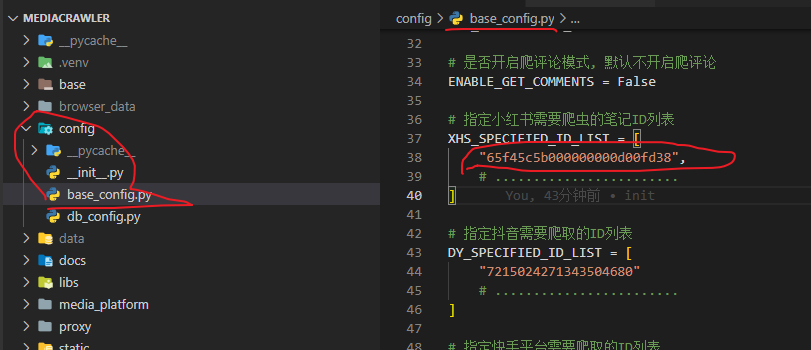
这里我配置了一条小红书的笔记ID,这里是个数据可以配置多个的。
好了,OK ,数据就被这么简单的抓取下来了。


作者还特意对数据存储做了封装,如果数据量大的时候存储起来可能就非常的方便了。
如果需求量很大,还可以对其源码进行研究改造,好了今天的学习就到这里了。
转自博客园,作者aehyok https://www.cnblogs.com/aehyok/p/18086730
该文章在 2024/3/27 17:48:43 编辑过






 400 186 1886
400 186 1886

